
Sort(2)
알고리즘 문제를 풀 때 사용하는 내장 sort 함수의 시간 복잡도는 O(NlogN)이다.
어떤 것이 있고, 어떻게 응용되어 사용되는지 알아보자.
O(NlogN)인 정렬
병합 정렬

분할 정복을 이용한 정렬 방법으로 원소가 1개 또는 0개 남을 때까지 둘로 쪼갠 다음 쪼갠 순서의 역으로 정렬해 합친다.
분할 정복으로 구현하게 되고, merge(1, n) -> merge(1, n/2) merge(n/2+1, n) .. 처럼 된다.
예시를 보면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[37,26,48,2,19,98,11]
[37,26,48,2] + [19,98,11]
[37,26] + [48,2] / [19,98] + [11]
[37] + [26] / [48] + [2] / [19] + [98] / [11]
로 쪼갠 후
[37] + [26] → [26,37]
[48] + [2] → [2,48]
[19] + [98] → [19,98]
[26,37] + [2,48] → [2,26,37,48]
[19,98] + [11] → [11,19,98]
최종: [2,26,37,48] + [11,19,98] → [2,11,19,26,37,48,98]
의 결과가 나온다.
분할 과정을 보면 절반씩 나누기에 NlogN의 시간 복잡도를 가지게 된다.
병합 정렬의 가장 큰 장점은 값이 같은 기존의 데이터의 순서가 지켜지는 stable sort라는 것이다.
heap 정렬
heap 정렬은 적당한 gif가 없어서 생략했다.
heap이라는 이진트리 자료 구조를 이용한 정렬으로 가장 큰 값이나 작은 값을 꺼내며 정렬한다.
루트가 최댓값을 가지는 이진 트리라면 루트를 출력하고 끝 원소와 교환한 후 힙 크기를 줄이고, 루트를 내린다.
그러면 다시 힙 구조가 유지되고 힙의 크기가 1일때까지 반복한다.
heap을 만들 때 O(N), 추출할 때 각각 O(logN)고 N-1번 반복하므로 O(NlogN)의 시간복잡도를 가지는 방법이다.
quick 정렬
퀵 정렬은 병합 정렬과 비슷하게 나누고 정렬하지만 나누는 기준을 pivot이라는 적절한 원소로 한다.
그 후는 병합 정렬처럼 분할 된 분할 리스트에 대해 또 pivot을 잡고 나누는 과정을 반복한다.
부분 리스트의 크기가 0이나 1일 때 까지 반복하면 정렬이 된 상태가 된다.
이 quick 정렬은 pivot을 선택하는 과정이 정렬 알고리즘의 효율을 결정한다.
만약 계속해서 최솟값이나 최댓값을 pivot으로 선택한다면 O(N^2)의 시간 복잡도를 가지게 된다.
N번의 pivot 선정과 각각 N개의 데이터를 확인해야 하기 때문이다.
그렇기에 pivot을 선택할 때 사용되는 방법은
median of three
구간의 처음, 중간, 마지막의 값을 보고 그 중 중앙값을 pivot으로 사용한다.
우리가 정렬하는 데이터는 어느정도 정렬이 되어있을 때가 많기에 그럴 때 효율적으로 pivot을 잡을 수 있다.Tukey’s ninther
위의 방법을 좀 더 발전시킨 것으로 3개는 표본이 부족해서 좋지 못한 데이터(뒤죽박죽 섞인 상태)에서는 효율적이지
않은 결과를 낼 수 있다.
그렇기에 왼쪽, 중간, 오른쪽으로 지점을 나눈 후 각각 세 부분에서 median of three를 사용한다.3-Way partition
중복 값이 많은 데이터에서 유리한 방법으로 기본 방법은 중복 값을 신경쓰지 않기에 정렬이 되어 있는 값들을 또 건드린다.
그렇기에 (< p), (== p), (> p) 3가지의 경우로 나눠서 같은 값의 덩어리를 한번에 축소할 수 있다.
병합, 힙, 퀵 정렬을 표로 보면 아래와 같다.
| 정렬 | 최선 | 평균 | 최악 | 안정성 | 추가메모리 | 실제 체감 속도(일반 배열) |
|---|---|---|---|---|---|---|
| 병합(Merge) | O(n\log n) | O(n\log n) | O(n\log n) | 안정 | O(n) 보조배열 | 보통 2등(큰 데이터에도 꾸준함) |
| 힙(Heap) | O(n\log n) | O(n\log n) | O(n\log n) | 불안정 | O(1) (제자리) | 셋 중 가장 느린 편 |
| 퀵(Quick) | O(n\log n) | O(n\log n) | O(n^2) | 불안정 | O(1) (제자리) | 보통 1등 (좋은 피벗/3-way 시) |
우선 병합 정렬은 두 개의 정렬 구간을 연속으로 접근하기에 캐시 접근에서 유리하다.
하지만 정렬 데이터 크기만큼의 추가 메모리가 필요하고, 작은 구간에서는 오버헤드가 있는 단점이 있다.
힙 정렬은 힙이라는 자료구조 특성 상 부모와 자식의 인덱스가 2배씩 차이가 나기에 캐시 접근이 좋지 않다.
또 heap에서 값을 빼고 바꾸면서 비교와 swap 과정이 많기에 오버헤드도 있어 보통 셋 중 가장 느리다.
하지만 어떤 데이터에서도 O(NlogN)이 보장이 된다는 것이 최대 장점이다.
마지막으로 퀵 정렬은 같은 배열안에서 부분을 나누므로 캐시 접근이 유리하고 평균적으로 가장 빠르다.
현실 데이터는 기본적으로 어느정도 정렬이 되어있기에 pivot 설정만 잘 하면 가장 좋은 알고리즘이 될 수 있다.
하이브리드 정렬
퀵은 빠르지만 최악이 O(N^2)이고, 병합은 안정적이지만 추가 메모리, 힙은 시간 보장이 되지만 체감이 느리다
이 단점들을 보완해서 더욱 좋은 알고리즘을 만들기 위한 하이브리드 정렬이 개발된다.
Intro sort
C++의 sort는 보통 Intro sort라는 퀵 정렬, 힙 정렬, 삽입 정렬로 이루어진 정렬을 사용한다.
sudo code로 보면
procedure sort(A : array):
let maxdepth = ⌊log2(length(A))⌋ × 2
introsort(A, maxdepth)
procedure introsort(A, maxdepth):
n ← length(A)
if n < 16:
insertionsort(A)
else if maxdepth = 0:
heapsort(A)
else:
p ← partition(A) // assume this function does pivot selection, p is the final position of the pivot
introsort(A[1:p-1], maxdepth - 1)
introsort(A[p+1:n], maxdepth - 1)
출처: https://en.wikipedia.org/wiki/Introsort
우선 길이가 16보다 작다면 삽입 정렬을 하는데,
길이가 작은 데이터에서는 삽입 정렬이 O(NlogN) 정렬보다 빠르기 때문이다.
병합은 보조 배열, 퀵은 분할과 재귀, 힙은 heapify 점프에 의한 오버헤드가 발생하지만 삽입 정렬은
연속된 메모리에 대해 비교 및 이동을 하기 때문에 오버헤드가 없어서 시간 복잡도가 O(N^2)임에도 더 빠르다.
아니라면 퀵 정렬을 하는데, 분할하면서 재귀 호출의 깊이가 2logN보다 커지면 현재 쪼갠 데이터의 길이를 확인한다.
만약 16보다 작으면 그대로 놔두고, 16보다 크다면 힙 정렬로 정렬을 한다.
퀵 정렬의 최악은 O(N^2)이기에 2logN번까지 확인하고 넘어가면 최악 case에 가깝다고 여기고
O(NlogN)이 보장되는 힙 정렬로 대체해서 실행하는 것이다.
이 과정을 거치면 대부분의 리스트가 정렬이 된 상태이고 아직 정렬이 안되어 있던 16보다 작은 부분 리스트들을
삽입 정렬을 통해 정렬해주면 Intro sort가 마무리된다.
위에서 기준을 16이라고 놓았는데 컴파일러마다 8~32 정도로 기준 값은 조금씩 다르다고 한다.
Tim sort
파이썬 list.sort()/sorted(), 자바 객체 배열이 사용하는 정렬로 이미 있는 정렬 구간을 최대한 활용한다.
stable sort인 삽입 정렬과 병합 정렬을 결합했기 때문에 Tim sort도 stable sort이다.
참고 자료 : https://d2.naver.com/helloworld/0315536
Tim sort의 최적화 기법은 Run이 있다.
run은 모든 원소들이 증가하거나 감소하는 덩어리이다.
배열을 받고, 삽입 정렬을 통해서 최소 run의 크기 만큼의 덩어리로 나누고, run의 크기를 넘어갔는데
뒤의 원소가 삽입 정렬 필요없이 계속 오름차순이나 내림차순으로 나온다면 그것도 run에 추가한다.
이 때 최소 run의 크기를 minirun이라고 부른다.
예시로 2^2 크기의 run을 만들어보면
1
[10 13 9 15 18 21 13 8 5 11 3]
우선 10, 13은 커지는 배열이므로 minirun만큼의 크기를 오름차순으로 만들면
1
[9 10 13 15]
이 된다. 그러고서 뒤를 보면 18, 21도 15에 이어서 붙이면 오름차 순이므로 run의 크기는 6이 된다.
1
[9 10 13 15 18 21]
다음 13, 8은 감소하므로 minirun만큼을 내림차순으로 만들면
1
2
[13 11 8 5] 이고, 3도 뒤에 붙일 수 있으므로
[9 10 13 15 18 21][13 11 8 5 3]
의 형태로 나눌 수 있게 되는 것이다.
minirun의 크기는 삽입 정렬이 효율적인 크기인 2^5~2^6으로 정한다고 한다.
그 다음 감소하는 배열은 뒤집어서 오름차순으로 만들어 merge sort를 할 준비를 마친다.
merge sort는 run의 개수가 2^x 개인 것이 좋기에 minirun의 크기를 유동적으로 정해서 사용하게 된다.
Merge 과정에서도 여러 기법들이 사용되는데
우선 위에서 봤든 run의 크기는 minirun에서 추가로 원소들이 붙을 수 있기 때문에 각각 다르다.
그렇기에 비슷한 크기의 덩어리가 merge 되도록 조작이 필요하다.
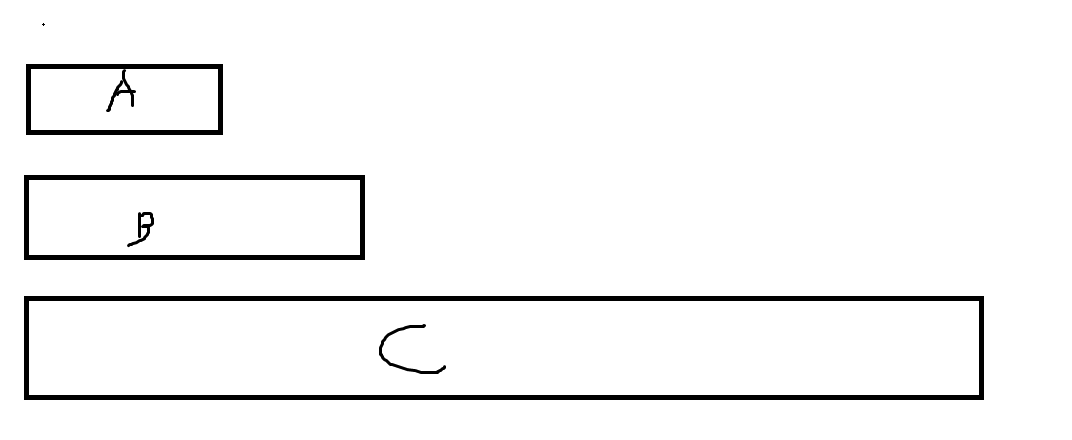
run을 저장할 때 stack을 이용하는데 가장 위의 3개를 A, B, C라고 하자.
|X|를 X의 크기라고 하면 |A|+|B| < |C|, |A| < |B|의 조건에 맞도록 스택에 저장한다.
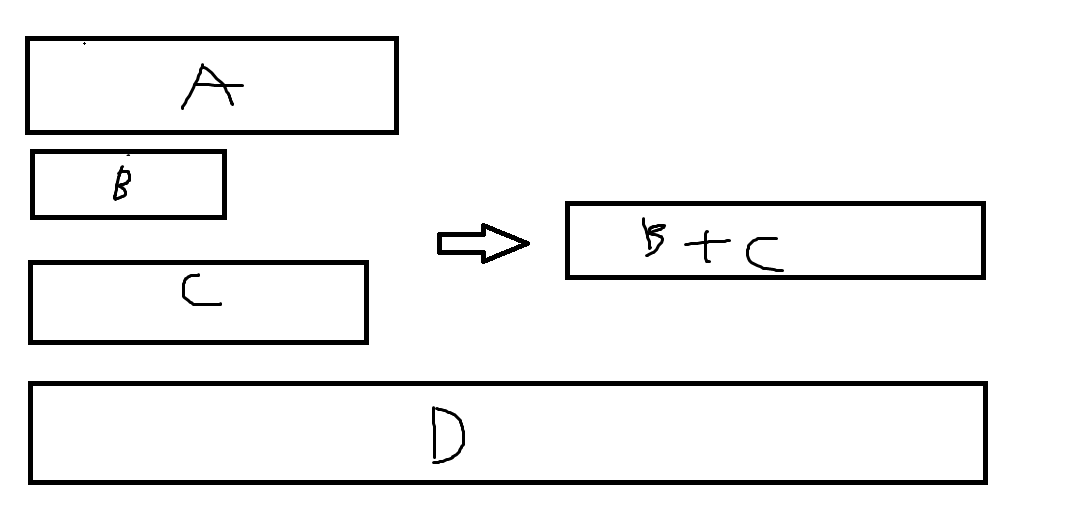
이 상태에서 조건에 맞지 않는 run(A)이 들어오면 우선 B를 A와 C 중 작은 것과 merge한다.
이렇게 조건에 맞을 때까지 위의 과정을 가진다.
B를 기준으로 인접한 run을 확인하고 B와 크기가 비슷한 것을 병합하며 run들을 조건에 맞춰 관리해서
효율을 중시하면서도 스택의 크기를 조절해 메모리를 관리하는 역할도 한다.
또 |A|+|B| < |C|로 관리하는데 이는 피보나치 수와 닮아있는 형태이다.
스택에 담겨있는 run은 R_1, R_2.. 로 보면 R_1+R_2 < R_3.. R_i+R_i+1 < R_i+2로 정리할 수 있다.
각 i번 째 run의 길이는 i번 째 피보나치 수보다 크므로 R_n의 크기가 1억이어도 스택의 크기는 40이하다.
이 역시 비슷한 run들을 모아서 merge 하면서도 메모리를 관리할 수 있다.
마지막으로는 merge하는 방법에서 사용하는 트릭이다.
병합 정렬의 가장 큰 문제점은 추가 데이터가 정렬 배열만큼 필요하다는 것이었다.
우선 추가 데이터를 줄이기 위해 run A와 run B가 있을 때 더 작은 run을 복사한다.
다음 투 포인터 알고리즘처럼
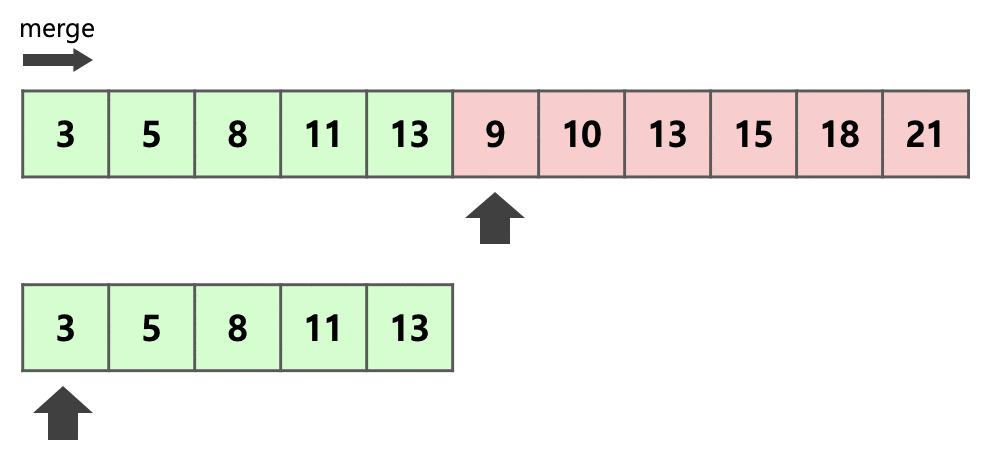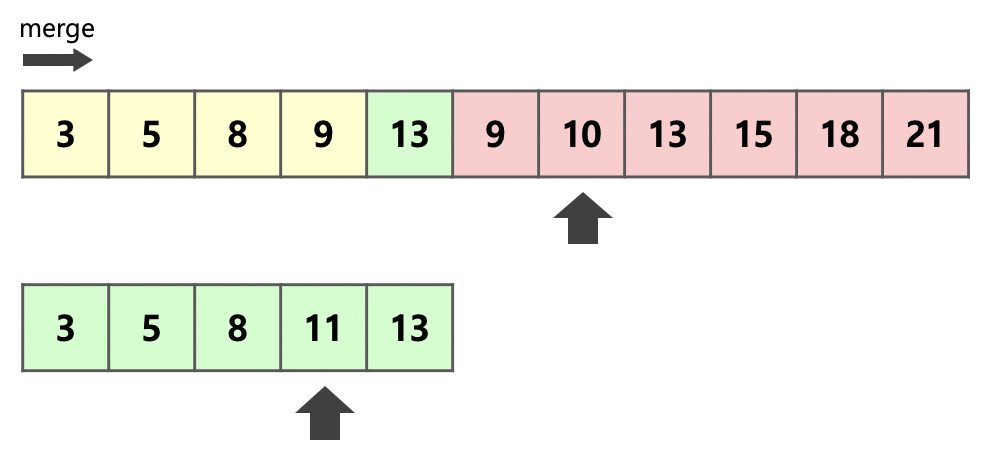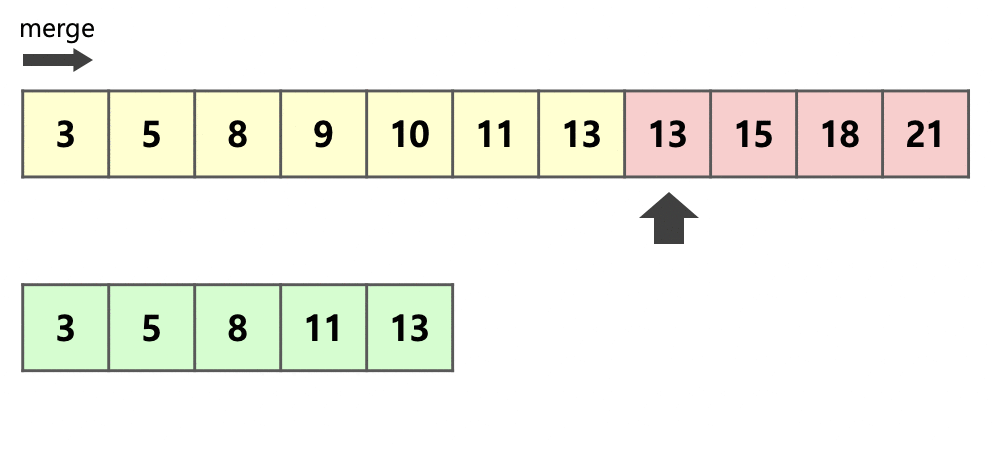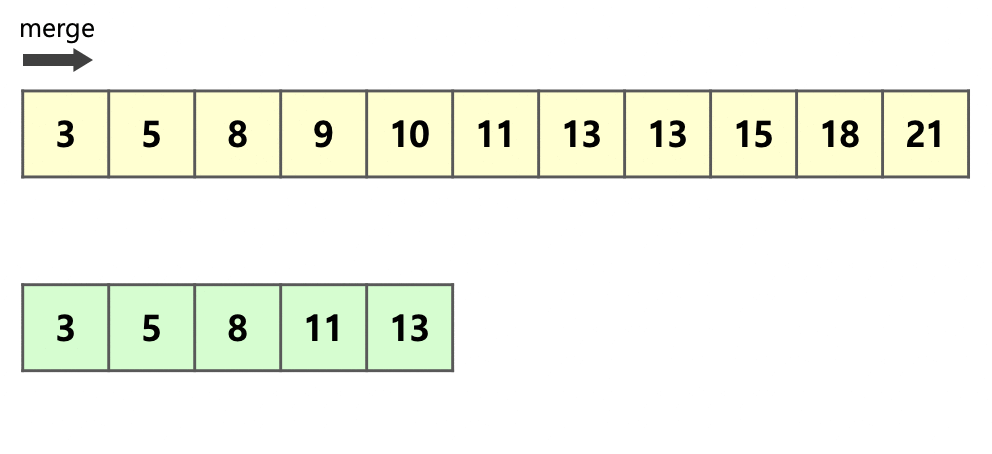
비교하면서 넣으면 O(N)이긴 해도 작은 메모리를 이용해서 merge를 할 수 있다.
또 실생활의 데이터는 무작위성이 떨어지기 때문에 run 2개를 merge할 때 한 run을 계속 참조할 가능성이 높다.
그렇기에 Galloping이라는 최적화를 사용하는데 위에서 화살표를 옮기면서 원소를 넣을 때
3번 연속 같은 run에서 merge를 했다면 galloping mode로 탐색을 해서 1, 2, 4.. 2^k 씩 화살표를 옮긴다.
그 다음 병합되지 않는 순간이 오면 이전으로 돌아가서 들어갈 원소를 찾는다.
이진 탐색과 비슷하다고 볼 수 있고
이렇게 기본 정렬들과 트릭들을 합쳐져서 더 효율적이게 정렬을 하는 Tim sort였다.
라이브러리나 내장 함수로 사용하고 있던 sort()의 최적화를 위해 여러 방법이 사용되고 있던 것이 신기하다.