
C언어 (4) 자료형2
정수형 변수에 이어 실수형 변수를 알아보자.
자료형 변환에 대해서도 알아보자.
| 자료형 | 키워드 | 바이트 수 | 범위 |
|---|---|---|---|
| 정수형 | short | 2 | -32,768 ~ 32,767 |
| 정수형 | int | 4 | -2,147,483,648 ~ 2,147,483,647 |
| 정수형 | long | 4 또는 8 | -2,147,483,648 ~ 2,147,483,647 4와 8은 os에 따라 다름. |
| 정수형 | long long | 8 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| 부호 없는 정수형 | unsigned short | 2 | 0 ~ 65,535 |
| 부호 없는 정수형 | unsigned int | 4 | 0 ~ 4,294,967,295 |
| 부호 없는 정수형 | unsigned long | 4 또는 8 | 0 ~ 4,294,967,295 4와 8은 os에 따라 다름. |
| 부호 없는 정수형 | unsigned long long | 8 | 0 ~ 18,446,744,073,709,551,615 |
| 실수형 | float | 4 | 약 ±3.4E-38 ~ ±3.4E+38 |
| 실수형 | double | 8 | 약 ±1.7E-308 ~ ±1.7E+308 |
| 문자형 | char | 1 | -128 ~ 127 |
| 부호 없는 문자형 | unsigned char | 1 | 0 ~ 255 |
| 논리형 | bool | 1 | true(1) 또는 false(0) |
실수형 변수
실수형 변수는 1.5, 3.141592 같은 실수를 저장하고 float, double 등이 있다.
그런데 위의 표를 보면 float는 int와 같은 4바이트를 할당받지만 범위는 아주 다르다.
같은 4바이트를 어떻게 사용하기에 ±3.4E-38 ~ ±3.4E+38라는 범위를 표현할 수 있을까?
컴퓨터가 실수를 표현하는 방식에는 고정 소수점 방식과 부동 소수점 방식이 있다.
고정 소수점
고정 소수점 방식은 정수형을 저장했던 것과 크게 다르지 않게 정수부와 소수부를 나누어 저장하는 것이다.
4byte=32비트가 있으면 최상위 비트는 부호 비트, 그 뒤 15비트는 정수, 나머지 16비트는 소수부로 쓸 수 있다.
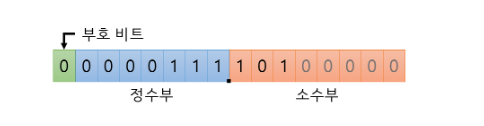
이진수에서 소수부는 어떻게 표현이 될까? 0.1은 1/2, 0.01=1/4와 같다.
십진수 13.6875를 이진수로 바꾸면 정수 부분은 1101이고, 소수 부분은 0.6875=(0.5*1)+(0.25*0)+(0.125*1)+(0.0625*1)이므로 1101.1011로 바꿀 수 있다.
그러면 정수 범위는 2^-15~2^15이므로 -32768~32768이고, 소수 범위는 1/2^16 = 0.0000152 까지 표현 가능하다.
정확도 측면에서 0.3을 이진수로 표현한다고 하면 0.0100110011001100… 이 되고 이는 0.29998779296875이다.
32비트 고정 소수점 환경에서는 0.3을 표현하기 위해선 무한 소수처럼 늘어지는데 표현할 수 있는 최소 단위가
0.0000152이기에 10^-5 정도의 오차가 생기는 것이다. 또, 정수부의 범위가 너무 작다는 단점을 가지고 있다.
부동 소수점
부동 소수점 방식은 실수를 표현할 때 지수 표기법을 이용한다.
지수 표기법이란? 기초 사항에서 한 번 봤는데 123.45라는 수를 1.2345x10^2로 보고 1.2345e2로 표기하는 것이다.

그림에서 S는 부호 비트, E는 1.2345e2에서 2를 나타내는 지수 비트, M은 실제 값을 저장하는 가수 부분이다.
E(8bit)로 표현할 수 있는 지수는 (-2^7~2^7)로 -127~128이다.
지수도 음수가 될 수 있기 때문에 E의 가장 첫 bit도 지수의 부호 비트로 사용된다.
위에서 본 13.6875를 이진법 부동 소수점으로 표현하면 1.1011011e11이다. (= 1.1011011e3)
그렇다면 E에서 표현할 수 있는 지수가 -127~128라는 것은 최대 2^128까지 표현이 가능하다는 것이고
log(2^128)=38.5…이다. float의 범위가 약 ±3.4E-38 ~ ±3.4E+38인 이유다.
double로 보면 E가 11bit이므로 최대 2^1024까지 표현 가능하고, log(2^1024)=308.25…이다.
정확도에 관련이 있는 것은 실제 값을 저장하는 부분인 M이다.
M은 1.xxxx 형태이기에 1은 생략하고 소수점 부분만 저장한다.
1.1011011e11를 바꾸면 E에는 11(10진수 3), M(가수 부분)에는 1011011(소수점 이후)만이 저장되는 것이다.
float의 M은 23bit가 할당되고, 첫 번째 bit는 1/2, 두 번째는 1/4를 표현한다.
마지막 bit는 1/2^23을 표현하게 되고 이는 0.000000119..이다.
이것이 float가 표현할 수 있는 가장 작은 숫자가 된다.
그러므로 float의 유효 범위는 10^-6이다.
double은 52bit이고, 1/2^52는 2.22e-16으로 유효 범위는 10^-15이다.
1
2
3
4
5
6
7
8
9
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
float a = 1.234512345123451234512345;
double b = 1.234512345123451234512345;
printf("%.20f\n%.20lf", a, b);
return 0;
}
실행해보면 1.23451232910156250000, 1.23451234512345120464가 출력돼 유효 범위를 확인 할 수 있다.
또 실수 표현 방식의 문제점이 하나 더 있다.
1
2
3
4
5
6
#include <stdio.h>
int main() {
float a = 0.3;
printf("%.20f\n", a);
return 0;
}
위의 코드를 실행해보면 0.30000001192092895508 유효 범위 이후로 이상한 값들이 출력된다.
0.3을 이진수로 표현한다고 하면 0.01001100110011001100…으로 끝나지 않기에 정확히 표현할 수 없는 것이다.
그렇기에 보통 프로그램으로 실수를 이용할 때 10^-9정도의 오차부턴 허용하게 한다.
오버플로우와 언더플로우
overflow란 주어진 범위를 넘는 것을 의미하는데, underflow는 무엇일까?
실수형 변수에는 너무 작아 표현하지 못하는 범위도 있다. float를 기준으로 지수의 최소 범위는 2^-128이다.
가수 부분의 최소는 1/2^23으로 10^-6정도 된다. 그러면 표현할 수 있는 가장 작은 값은 10^-6 x 2^-128=1e-45정도이다.
이보다 작은 값은 float형 변수에 저장할 수 없고, 이를 underflow라고 부른다.
1
2
3
4
5
6
7
#include <stdio.h>
int main() {
float a=1e39, b=1e-48;
printf("%f\n", a);
printf("%f", b);
return 0;
}
1
2
inf
0
이라는 결과가 나온다.
실수형 변수에서 overflow되면 무한대를 의미하는 inf, underflow는 0을 출력한다.
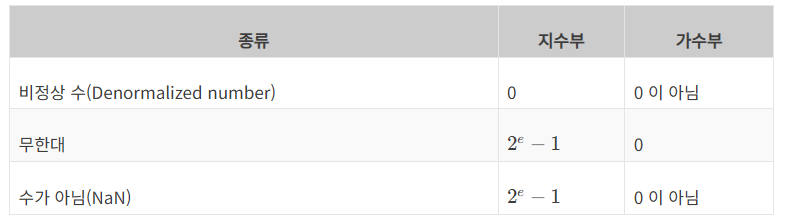
위의 부동소수점 저장 방식에서 지수부가 0이며 가수부가 0이 아닐 때가 언더플로우
지수부가 최대이며 가수부가 0이면 오버플로우, 지수부가 최대이며 가수부가 0이 아니면 NaN이다.
이 NaN은 0/0, inf x inf, inf x 0과 같은 값을 정할 수 없는 연산에 의해 발생한다.
double을 선호?
float과 double 중 더 선호하는 자료형은 무엇일까?
유효 범위의 차이 때문에 double이 선호된다.
float은 6자리밖에 안되지만 double은 15자리까지는 정확하게 표현할 수 있기 때문이다.
자료형마다 입출력 형식도 달라지는데 float는 %f, double은 %lf이다.
자료형 변환
c언어는 자료형이 다양하기 때문에 복합적인 연산이 필요하면 다른 자료형 간 연산을 할 수도 있다.
1
2
3
4
5
6
7
#include <stdio.h>
int main() {
int num = 100;
float a = 0.25;
printf("%f\n", a+num);
return 0;
}
결과는 100.25로 자동으로 int+float = float형으로 자료형을 변환해준다.
1
2
3
4
5
6
#include <stdio.h>
int main() {
int num1 = 3.14;
printf("%d\n", num1);
return 0;
}
하지만 int num에 실수 3.14를 넣고 출력을 한다면 소수점은 사라지고 3만 남는다.
1
2
3
4
5
6
7
8
#include <stdio.h>
int main() {
int num1 = 100;
int num2 = 3;
double res = num1 / num2;
printf("%lf\n", res);
return 0;
}
위의 코드는 int형/int형이기에 결과도 int형이고, res=33이 들어간다.
여기서 실수형 답을 낼 수 있을까? (double) num1 / num2로 바꿔주면 결과가 나온다.
프로그램이 아니라 사용자가 강제로 int형을 double로 변환시키는 강제 형변환이다.
1
2
3
4
5
6
7
8
#include <stdio.h>
int main() {
int num1 = 100;
int num2 = 3;
double res = (double)num1 / num2;
printf("%lf\n", res);
return 0;
}
계산 과정에서만 num1은 double형인 100.000000으로 바뀌고 double/int의 결과는 double이다.
그렇게 원하는 값인 33.333333을 출력할 수 있다.
화이트 스페이스(white space)
1
2
3
4
5
6
7
8
9
10
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int num;
char ch;
scanf("%d", &num);
scanf("%c", &ch);
printf("숫자 : %d 문자: %c", num, ch);
return 0;
}
프로그램을 짜다보면 숫자와 문자를 순서대로 받아야 할 상황이 온다.
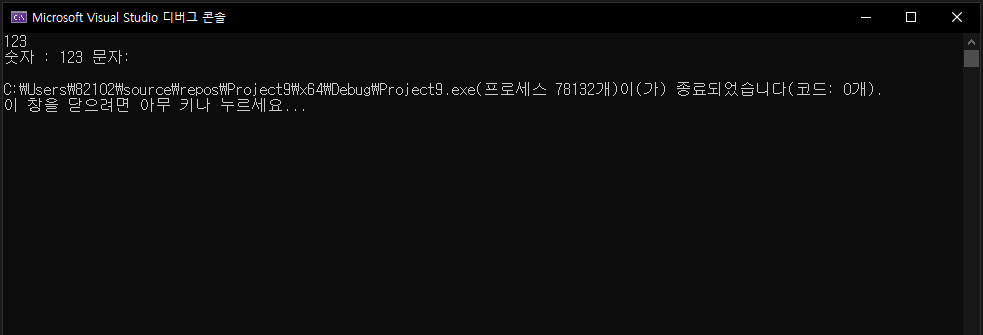
그런데 이 코드를 돌리면 숫자는 입력이 잘 되지만 문자를 받는 부분이 동작을 안한다.
우리가 키보드로 입력할 때 123을 친 다음 엔터를 칠 것이다.
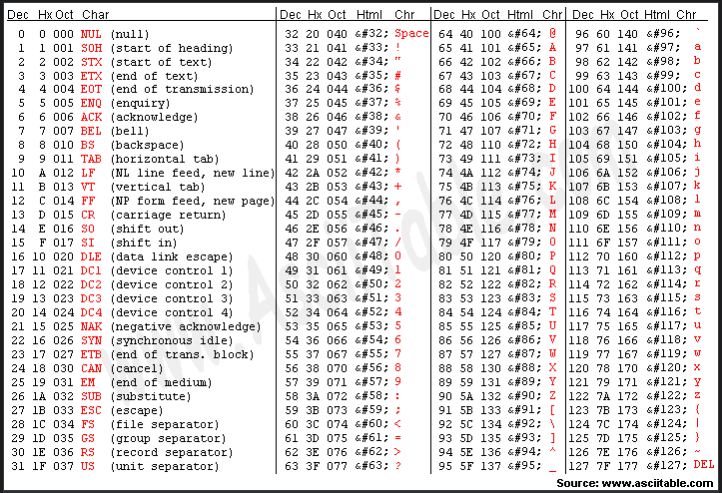
저번에 문자는 아스키코드로 변환되어 숫자로 저장이 된다고 했다.
그런데 엔터는 ‘\n’(줄바꿈 문자)와 같은 역할을 하고 아스키코드 표의 10번 LF와 같다.
즉 ‘\n’는 10이라는 값을 가지고 있는 것이다.
그렇기에 위의 코드에서 num에 123이 들어간 후 엔터가 %c에 들어가 새로 한 줄이 만들어졌다.
이는 우리가 원하는 실행 결과가 아니다.
그래서 다른 입력을 받은 후 한 개의 문자를 받기 위해서는 getchar()라는 한 글자만 받는 함수를
이용해서 ‘\n’를 받아줘야한다.
1
2
3
4
5
6
7
8
9
10
11
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int num;
char ch;
scanf("%d", &num);
getchar();
scanf("%c", &ch);
printf("숫자 : %d 문자: %c", num, ch);
return 0;
}
이렇게 바꾸면 getchar()가 엔터키를 받아 원하는 문자를 입력할 수 있어 정상적으로 실행이 된다.
자료형과 c언어가 어떤 형식으로 값들을 저장하는지 보았다.
특히 white space 문제는 꽤나 헷갈릴 수 있고 실수하기도 좋기에 잘 알아야한다.
다음에는 연산자와 음수를 저장하는 방법을 알아보자.