
블록체인이란 무엇인가?
라고 하면 데이터를 ‘블록’이라는 소규모 단위로 묶어 chain으로 연결하고
이를 여러 컴퓨터에 동시에 분산·저장하는 분산 데이터 저장 기술이다.
중앙 서버 없이 네트워크 참여자들이 공동으로 기록을 관리하고,
데이터 위변조가 매우 어렵고 투명한 ’탈중앙화’ 거래 시스템을 제공하고자 등장했다.
네트워크 내에서 정보를 투명하게 공유할 수 있도록 하는 데이터베이스 구조이며
블록체인의 데이터는 합의 없이 임의로 수정하거나 제거하기 매우 어렵다.
등장 배경
어째서 이런 기술이 필요해졌을까?
2008년 미국의 서브프라임 모기지 사태로 일어난 전세계적인 금융 위기와 닿아 있다.
기존 중앙화 금융 시스템과 중개 기관에 대한 신뢰를 크게 흔들었고,
중앙 기관의 통제가 없는 시스템이 이목을 받았다.
이런 상황에서 2008년 10월에 사토시 나카모토라는 가명의 인물이 중앙 서버나 관리자가 없는
P2P 분산 DB기반의 가상 화폐인 비트코인을 발표했다.
블록체인의 구조
블록은 여러 개의 거래 데이터와 메타데이터를 묶어 놓은 하나의 데이터 덩어리이다.
그리고 이 블록들이 이전 블록을 가리키는 방식으로 체인처럼 연결되어 있다.
블록은 크게 header와 body로 이루어져 있다.
아래는 비트코인 기준으로 단순화한 구조이다.
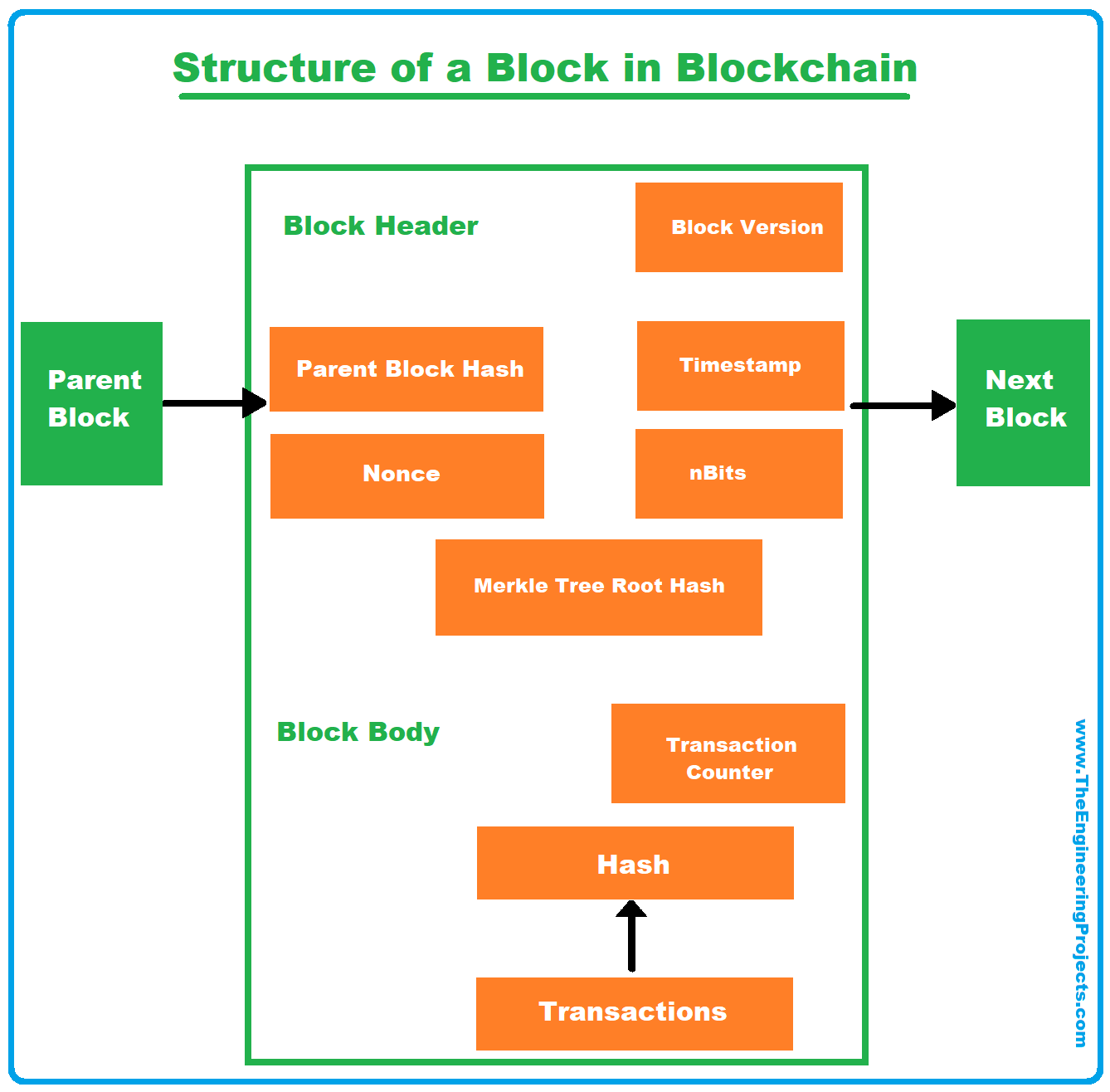
Header
- 이전 블록의 해시 값
- 바로 앞 블록의 내용을 해시한 값
- 이 값을 통해서 이전 블록과 이어진다.
- 블록이 만들어진 시간인 타임스탬프
- 블록들의 순서를 파악
- 블록 내부 트랜잭션들을 요약한 머클 루트 해시값
- 블록 안 거래들이 변조되지 않았는지 확인
- 블록 버전 정보
- 블록이 어떤 규칙과 형식을 따르는지 나타내는 값
- 프로토콜 업그레이드나 변경이 있을 때 해석 방식이 달라진다.
- 채굴 난이도 관련 값(nBits 등)
- PoW 체인에서는 블록 해시가 특정 목표값보다 작아야 하는데 그 목표이다.
- 조건에 맞는 블록 해시를 찾기 위해 사용하는 nonce 값
- 채굴자가 계속 바꿔 가며 해시를 다시 계산하는 값
Body
- 블록에 포함된 트랜잭션 개수
- 거래가 몇 개 들어 있는지를 나타낸다.
- 실제 트랜잭션 목록
- 사용자가 전송한 거래 데이터들이 실제로 들어 있는 부분
체인마다 구조가 조금씩 다르지만 비트코인을 기준으로는 이와 같다.
노드
노드는 블록체인 네트워크에 참여하는 컴퓨터다.
이 컴퓨터가 블록체인 데이터를 저장하고, 다른 컴퓨터와 통신하고 트랜잭션과 블록을 검증한다.
블록이 데이터 단위라면 노드는 데이터를 보관하고 전달하는 주체다.
노드는 새 트랜잭션을 받고, 규칙에 맞는지 검증한다.
블록에 대해서도 유효한지 검증하고 로컬에 저장하고, 다른 노드에 전파한다.
이렇게 여러 노드가 같은 데이터를 나눠 가지고 검증을 한다.
노드의 종류
풀 노드
블록과 트랜잭션을 직접 검증하고 현재 체인을 독립적으로 추적하는 노드이다.
처음 생성된 제네시스 블록부터 마지막 블록까지 모든 데이터가 있다.
그렇기에 스스로 거래 검증을 할 수 있지만, 많은 저장 공간이 필요하다.
라이트 노드
풀 노드는 너무 많은 저장 공간이 필요하기에 블록 헤더의 중요 데이터만 가지고 있고
거래는 가능하지만 독립적인 검증이 불가능해서 풀노드에 거래 데이터를 요청해 검증해야 한다.
데이터를 요청한 후 확인하는데 시간이 걸리지만 데이터 공간이 적게 필요하다.
채굴/검증자 노드
합의에 참여하는 노드로 이후에 다룰 합의 방법에 따라 다르다.
PoW에서는 채굴 노드가 블록을 만들기 위해 계산 경쟁을 하고
PoS에서는 검증자 노드가 스테이킹을 기반으로 블록 제안과 검증에 참여한다.
아카이브 노드
풀 노드에 추가해서 과거 상태 변화까지 거의 전부 보관한다.
풀 노드는 현재 상태 중심으로 저장이 되어 예전 상태는 새 상태로 덮이거나,
필요한 최소 정보만 남기고 정리하기에 옛날 블록 높이에서의 상태를 바로 꺼내기는 어렵다.
아카이브 노드는 상태가 바뀔 때마다 그 이전 상태들까지 계속 보존하기에
과거 블록 시점의 account/state trie 내용을 확인할 수 있다.
Merkle Tree
블록 안에는 많은 트랜잭션이 들어간다.
그렇다면 특정 거래가 정말 이 블록에 포함되어 있는지,
그리고 중간에 변조되지 않았는지를 어떻게 효율적으로 확인할 수 있을까?
이를 위해 사용하는 구조가 Merkle Tree이다.
머클 트리는 여러 데이터의 해시 값을 트리형태로 묶어 하나의 루트 해시값으로 모으는 구조다.
주로 트랜잭션 목록을 검증하기 위해 사용된다.
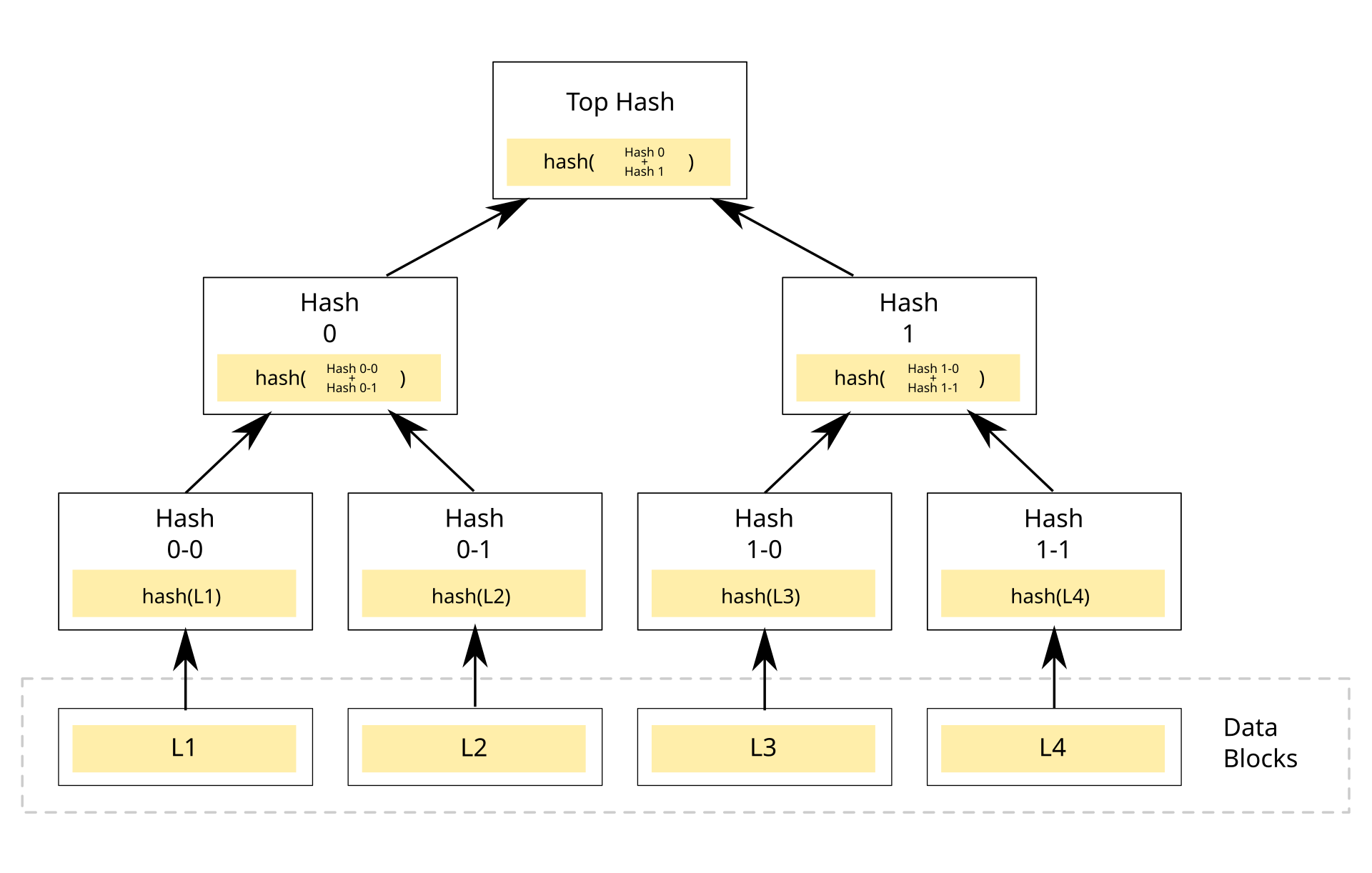
구조는
- 각 트랜잭션을 해시
- 인접한 두 해시 값을 합쳐서 다시 해시
- 최종으로 하나의 해시가 남을 때까지 반복하고 이 값이 머클 루트값이다.
트랜잭션이 4개일 때를 간단하게 보자. H는 해시함수이다.
h1=H(Tx1), h2=H(Tx2), h3=H(Tx3), h4=H(Tx4)이다.
h12 = H(h1 concat h2), h34 = H(h3 concat h4)
h1234 = H(h12 concat h34) 이며 h1234가 머클 루트가 된다.
만약 트랜잭션이 홀수개 있으면 짝을 맞추기 위해서 마지막 해시를 한 번 더 복제한 후 이를 다시 해시한다.
트랜잭션이 3개면 h33=H(h3 concat h3)을 통해 만들고 루트는 h1233이 된다.
사용하는 이유
이렇게 해시값을 가지고 거래를 다루기에 모든 거래를 하나의 해시로 요약이 가능하다.
트랜잭션이 하나만 바뀌어도 해시값이 바뀌기에 머클 루트도 바뀌며, 내부 데이터의 변조를 빠르게 파악 가능하다.
또한 모든 트랜잭션을 전부 확인하지 않아도, 특정 거래가 블록에 포함되어 있는지 효율적으로 증명할 수 있다.
이 때문에 저장 공간이 부족한 라이트 노드에서도 유용하게 활용된다.
머클 트리의 최종 결과값인 머클 루트는 블록 헤더에 저장된다.
즉 블록 헤더에 있는 머클 루트는, 그 블록 안에 포함된 모든 트랜잭션을 대표하는 요약값이라고 볼 수 있다.
따라서 블록을 검증할 때는 블록 안의 트랜잭션들로 머클 트리를 다시 만들고 그 결과가 헤더에 저장된 머클 루트와 같은지 확인함으로써 데이터의 무결성을 검사할 수 있다.
특정 거래를 효율적으로 증명하기
머클 트리는 가장 아래에 트랜잭션 해시가 있고, 올라갈수록 합쳐서 부모 해시가 있다.
특정 거래 tx_k가 블록에 포함되었는지 확인하기 위해서는 k에서 루트까지 올라가는 경로에 필요한 해시만 필요하다.
트랜잭션 8개의 머클 트리에는 h1~h8, h12~h78, h1234, h5678, h12345678 이 있다.
h3을 증명하기 위해서는 h4, h12, h5678만 있다면 머클 루트를 복구할 수 있고 비교를 하면 된다.
이것은 n개의 트랜잭션에 대해서 log(n)개만 필요하기에 효율적이다.
간단하게 블록체인에 대해 정리했고, 다음은 네트워크와 거래 흐름에 대해서 정리한다.